Threat intelligence is essential for mitigating phishing risks. By studying past attacks, organizations can identify patterns and indicators to anticipate and prevent future threats.
In this post, we explore URL pattern analysis, showing how it can streamline the collection of actionable intelligence and enhance your ability to detect and defend against phishing attacks.
The What and Why of URL Pattern Analysis
In essence, URL pattern analysis is the process of taking a large subset of phishing site URLs and attempting to identify patterns which can be used to cluster those URLs into groups, or “families”. To do this, you can ask yourself a series of questions, such as:
- Do any of these sites share the same (or similar) landing page names?
- What do the directory structures of each site look like? Are there any patterns or similarities?
- What about the content hashes? Are the hashes for any of these sites the same, either in raw or normalized form?
- Do any of the sites demonstrate traits consistent with common defensive tactics, such as directory generators, or URL parameters?
Simply by answering these questions, you can quickly group a very large subset of URLs into a much shorter list of URL families.
And here’s the thing. By doing this, you have effectively “shrunk” the phishing ecosystem. Instead of having to study each site individually, you can now analyze each distinct family for characteristics that might tie that group of phishing sites to a specific phish kit or actor.
Ultimately, this process will help you to identify the most significant current threats and campaigns, which will have a profound impact on the ROI for your detection and mitigation activities.
URL Pattern Analysis
In order to better understand how URL pattern analysis works, it may help to run through a simple example.
The table below contains nine real phishing site URLs, along with some basic information about each.

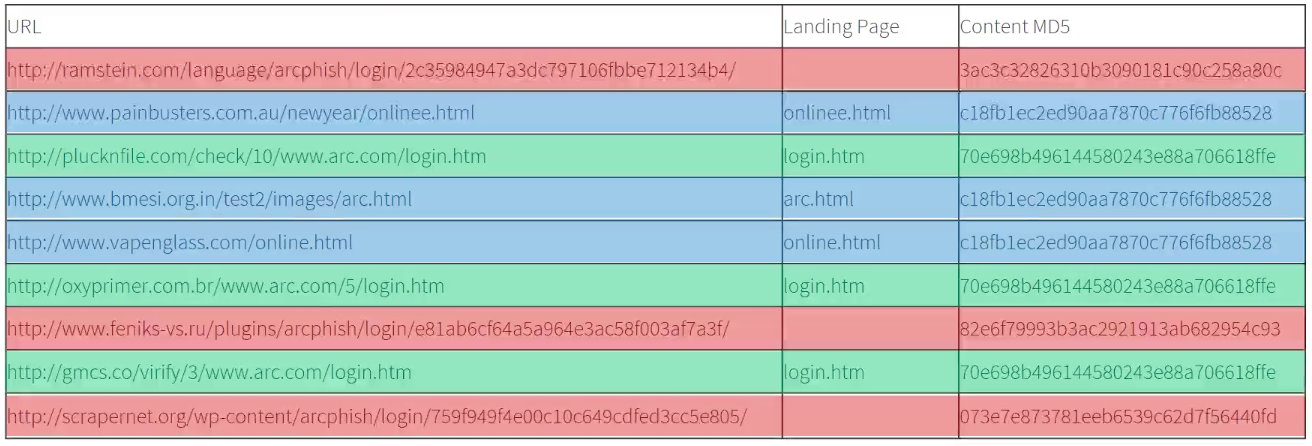
At first glance each of the URLs seems distinctly individual, but with a little analysis it quickly becomes apparent that they can be divided into clear groups.
For instance, three of the URLs share very similar directory structure (/www.arc.com/login/) and use identical page names: login.html
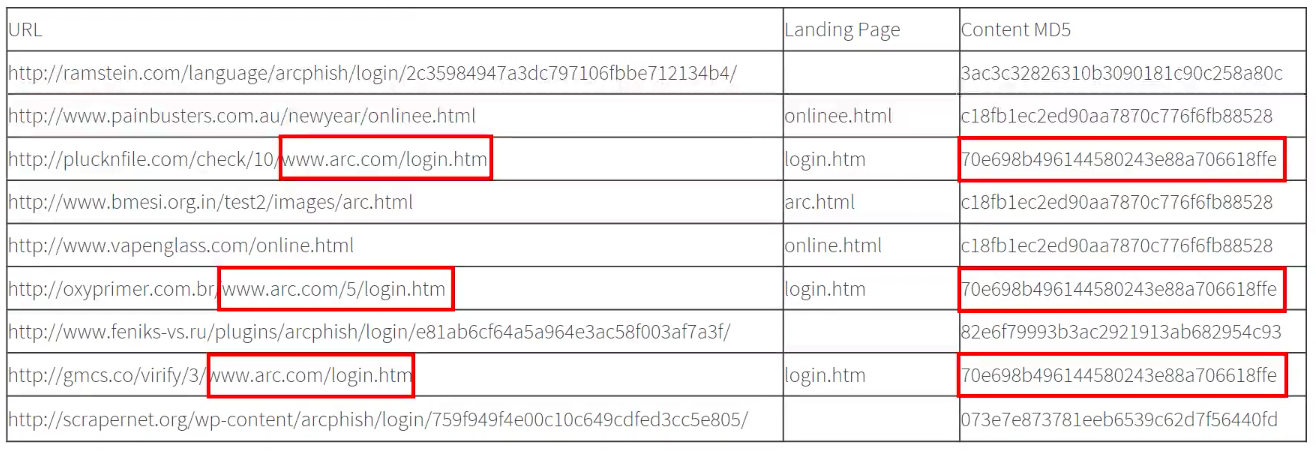
Taking the similarities a stage further, the hashes (Content MDS) are identical for each of the three URLs.
Based on these similarities, these sites can comfortably be grouped into a single family.
Next up, we have a second family highlighted in the table below:
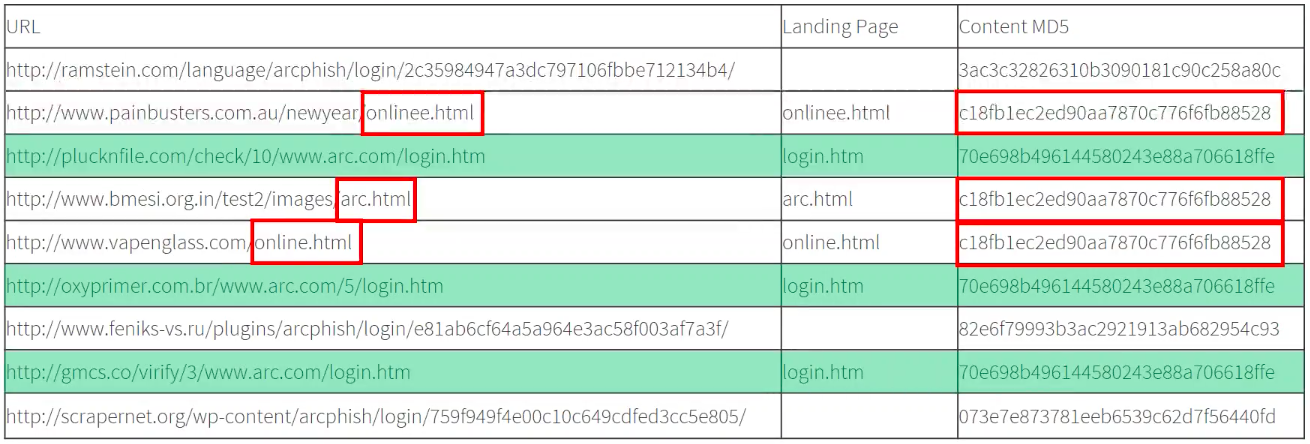
In this case it’s a little more difficult to identify similarities, because all three URLs have different landing page names, and show no real similarities in directory structure. In fact, pretty much nothing about these three URLs suggests an obvious link.
When we consider the page hashes, though, we see that once again they are identical for all three sites. This is something we see frequently in cases where a particular phish kit has been distributed freely over a long period of time. Over time, phishing actors have gradually modified the page names and directory structures used, but the actual page content (and thus page hashes) remains the same.
Finally, we can link the remaining three URLs into yet another distinct family. But once again, at first glance, it’s difficult to spot a clear link.
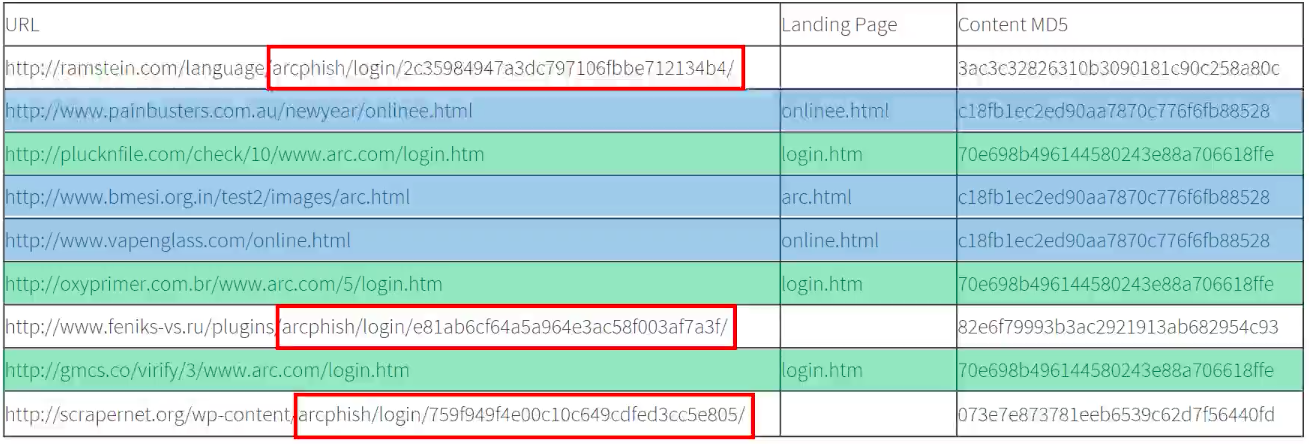
This time, each of the sites’ hashes are completely different, and there are no obvious similarities in the landing page names.
There is, however, a clear similarity in the URLs’ directory structures. First, each of the URLs contain the string /arcphish/login/, which is a strong indication that there is some link between the sites.
Even more significant, though, are the landing page names. These long, seemingly randomized page names are consistent with a particular style of directory generator, which dynamically generates a new directory for each individual visitor. Once the new directory has been created on the phish site’s host server, all of the necessary files are copied into it, and a unique URL is generated.
Why go to all that effort? Simple. Phishing actors know that by generating a unique URL for each individual user, they have a far better chance of evading router-based or browser-based blocking techniques.
Of course, there are plenty of phish kits and actors that make use of this technique. When combined with /arcphish/login/ string, though, it becomes clear that these three URLs are almost certainly linked to a single source.
Linking Isn’t the End of the Story
“Well, that’s great,” You might be thinking. “I’ve grouped my phishing URLs into a handful of families… now what?”
Here's the thing. URL pattern analysis is a tremendously valuable tool in the threat intelligence production process, but it isn’t intended to be used in isolation.
Grouping phishing URLs into a much smaller number of families you can save a lot of time and energy, because it enables you to focus your efforts on the specific phish kits and actors most likely to target your organization. But, of course, once the pattern analysis has taken place, you’ll still need to expend the time and resources necessary to fully understand your organization’s most pressing threats.
Ultimately, you’ll need to use the threat intelligence you’re producing to inform sensible and effective countermeasures. Phishing intelligence can (and should) be used to inform improvements to all manner of operational security functions, such as firewalls, advanced spam filters, and vulnerability/patch management systems.
But as we already know, there is only so much technical controls can do to thwart phishing attacks. Contact us today to learn how your organization could benefit from phishing threat intelligence.